

티스토리 뷰
이번에 만들어 볼 것은 phtyon을 이용한 코드인데,
먼저 cahtGPT가 뭔지 모른다면?
chatGPT 같은 경우는 최근에 오픈 ai라는 회사에서 만든 대화용 챗봇 인공지능 시스템이라고 생각하면
되는데, 인공지능 시스템이 되게 성능이 엄청나게 좋고 그리고 이것이 더 대단한 거는
파이썬 코드 같은 것들도 직접 코딩하지 않고 그냥 어떤 문장으로 시키고 싶은 말을 건네주면 chatGPT가 그에 대응되는
파이썬 코드를 만들어 준다느 것... 코딩하는 빡센 노가다를 일부 해소해 주는 것이 대단하다고 생각함
프로그래머 일을 대신주는 것이 정말 대단한 일이라고 생각한다.
당연히 chatGPT를 사용하기 위해서는 chatGPT 사이트에 들어와서 로그인 하고 회원가입하고 휴대폰 번호 인증하고,
로그인 화면까지 성공했을 때부터 시작된다.

일단 네이버에 'chatGPT'라고 검색하면 뉴스탭 부분을 들어가 본다.
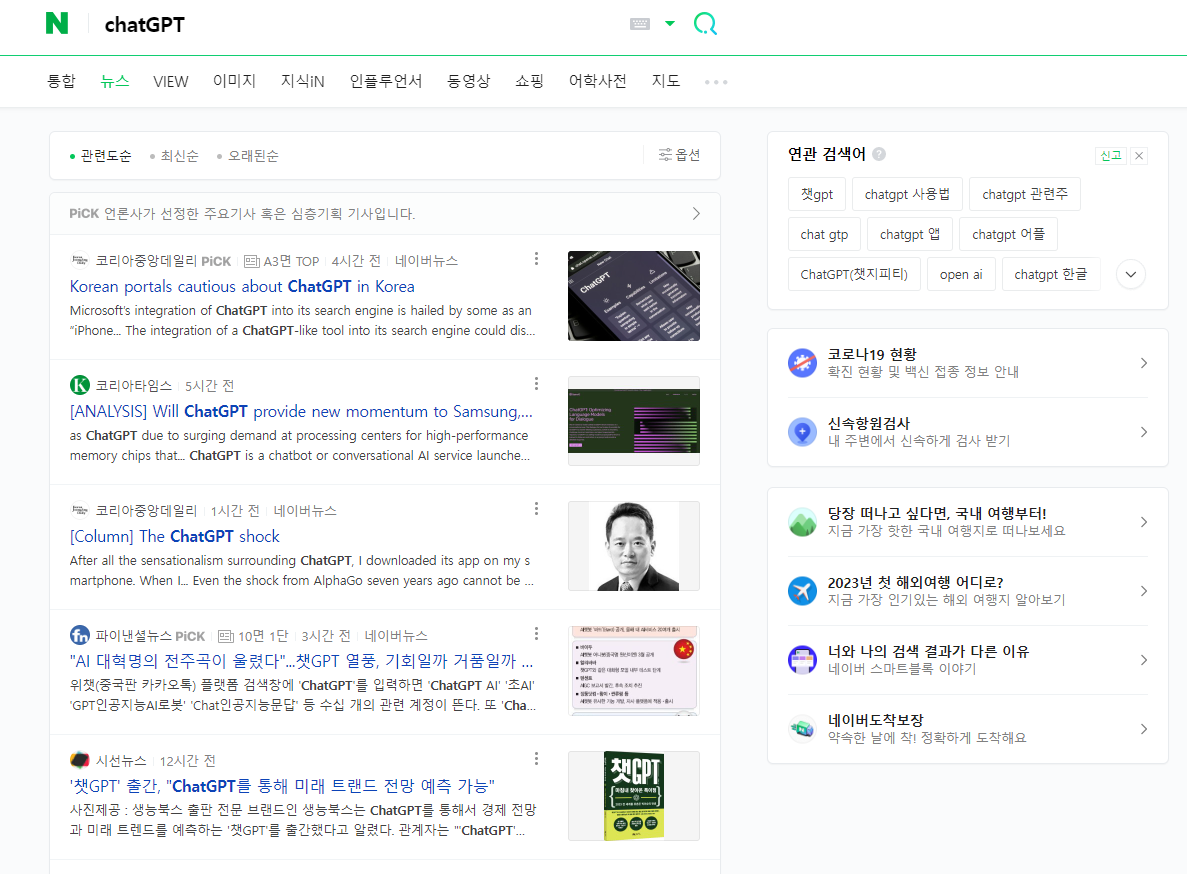
뉴스 부분에 나오는 뉴스의 헤드라인을 크롤링하는 것이 오늘의 목표다
이제 코드를 작성해야 하는데, chatGPT에게 정보를 프롬프트로 입력해 보자

실제 네이버 화면에서 F12키를 누르면 개발자모드에서 각 요소의 내용을 볼 수 있는데,
해드라인 부분은 'a.news_tit'라는 태그가 보인다. 저 태그를 이용해서 정보를 가져오도록 해본다.
https://search.naver.com/search.naver?where=news&sm=tab_jum&query=chatGPT 에서 a.news_tit 부분에 제목들을 추출하는 python 크롤링 스크립트를 작성해줘
위와 같이 입력하면 코드가 나온다.
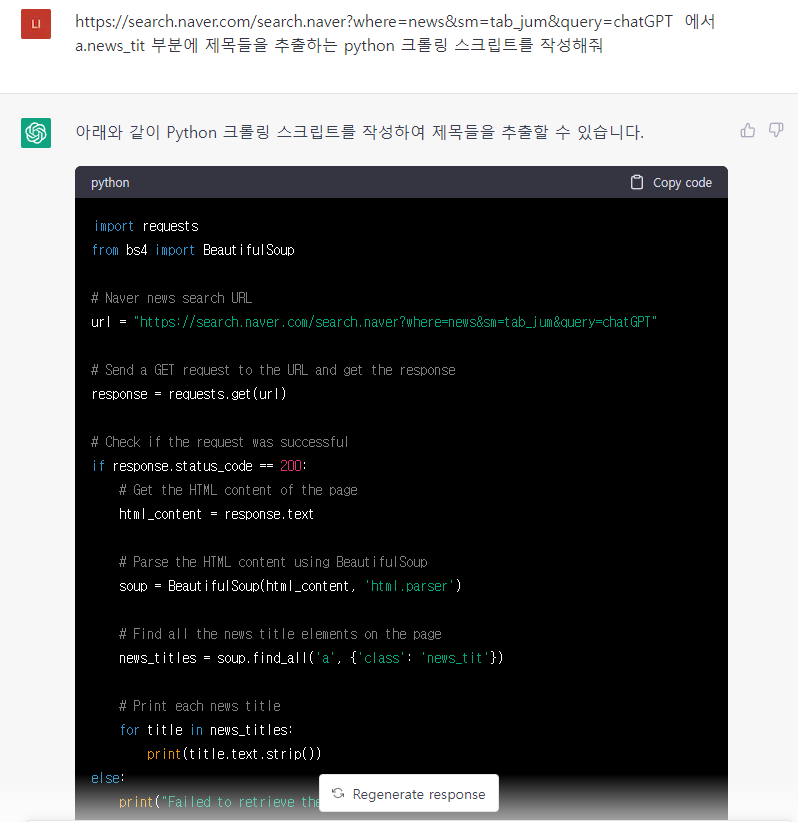
import requests
from bs4 import BeautifulSoup
# Naver news search URL
url = "https://search.naver.com/search.naver?where=news&sm=tab_jum&query=chatGPT"
# Send a GET request to the URL and get the response
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Get the HTML content of the page
html_content = response.text
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Find all the news title elements on the page
news_titles = soup.find_all('a', {'class': 'news_tit'})
# Print each news title
for title in news_titles:
print(title.text.strip())
else:
print("Failed to retrieve the page content")파이썬을 쉽게 실행하는 에디터를 제공하는 구글 colab을 검색해서 구글 아이디가 있다면 바로 '새노트'생성해서
파이썬을 쉽게 실행할 수 있다.
아까 생성한 코드를 넣고 좌측의 실행버튼( play 버튼 모양)을 누른다.

그러면 조금 기다리면 아래와 같이 결과가 나온다.

Korean portals cautious about ChatGPT in Korea [ANALYSIS] Will ChatGPT provide new momentum to Samsung, SK? [Column] The ChatGPT shock "AI 대혁명의 전주곡이 울렸다"...챗GPT 열풍, 기회일까 거품일까 [글로벌 리... '챗GPT' 출간, "ChatGPT를 통해 미래 트랜드 전망 예측 가능" [시론] ChatGPT가 대학 교육에 어떤 변화를 가져올까 ChatGPT, AI 발전 가속화 VS 사회적·윤리적 침해 [노컷체크] 챗GPT로 팩트체크도 가능할까? 챗지피티(ChatGPT)가 내 업무도 대신?...알파고보다 파장 커 인간 일자리 위협... 생능북스, 대화형 인공지능 ChatGPT 통한 미래 다룬 '챗GPT' 출간
위는 실제 나온 텍스트인데, 글이 붙어 있어 읽기가 좀 그렇다. 이러면 다시 명령어를 넣어준다.
chatGPT 프롬프트창에 이렇게 입력해 본다.
'print문을 한줄씩 띄어서 출력해줘'

기존코드에서 아래 print 문의 구조가 바뀐것을 확인할 수 있다.
이것을 그대로 복사해서 다시 구글colab에 넣고 실행하면
Korean portals cautious about ChatGPT in Korea
[ANALYSIS] Will ChatGPT provide new momentum to Samsung, SK?
[Column] The ChatGPT shock
"AI 대혁명의 전주곡이 울렸다"...챗GPT 열풍, 기회일까 거품일까 [글로벌 리...
'챗GPT' 출간, "ChatGPT를 통해 미래 트랜드 전망 예측 가능"
[시론] ChatGPT가 대학 교육에 어떤 변화를 가져올까
ChatGPT, AI 발전 가속화 VS 사회적·윤리적 침해
[노컷체크] 챗GPT로 팩트체크도 가능할까?
챗지피티(ChatGPT)가 내 업무도 대신?...알파고보다 파장 커 인간 일자리 위협...
생능북스, 대화형 인공지능 ChatGPT 통한 미래 다룬 '챗GPT' 출간
이렇게 출력된다.
결과를 csv로 저장하고 싶다면 다시 명령을 추가하면 된다.
'결과를 csv파일로 저장해줘' 라고 명령해 본다.

코드를 다시 구글 colab에 넣고 실행하면 결과는
왼쪽창에 보면

news_titles.csv파일이 생성된 것을 확인할 수 있다.
다운로드해서 보면

추출한 헤드라인이 한줄씩 저장되어 있는 csv 파일이 생성된 모습을 확인하실 수 있다.
이렇게 chatGPT를 활용하면 크롤링 스크립트를 작성한 능력이 없더라도 chatGPT에게
요청해서 원하는 부분을 크롤링하는 파이썬 스크립트를 간편하게 작성하실 수 있다.
완성된 코드도 올려놓으니, 필요한 분들은 가져다 쓰시길 바란다.
import csv
import requests
from bs4 import BeautifulSoup
# Naver news search URL
url = "https://search.naver.com/search.naver?where=news&sm=tab_jum&query=chatGPT"
# Send a GET request to the URL and get the response
response = requests.get(url)
# Check if the request was successful
if response.status_code == 200:
# Get the HTML content of the page
html_content = response.text
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Find all the news title elements on the page
news_titles = soup.find_all('a', {'class': 'news_tit'})
# Write the news titles to a CSV file
with open('news_titles.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['title']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for title in news_titles:
writer.writerow({'title': title.text.strip()})
else:
print("Failed to retrieve the page content")코딩을 못해도 아이디어가 있으면 충분히 도전할 수 있지만,
코딩의 기본적인 지식이 있다면 작성시간을 획기적으로 줄여주는 정말 좋은 도구가 될 것이다.
chatGPT 너무 사랑스럽다~
모두모두 즐코딩~
'IT tech Coding > chatGPT' 카테고리의 다른 글
| chatGPT 3.5의 python 학습 버전은? (0) | 2023.12.01 |
|---|---|
| [뤼튼] 무료화 선언 지지한다. (0) | 2023.11.29 |
| chatGPT에게 조언받는 나의 질문들 모음 (0) | 2023.05.14 |
| 사람들은 chatGPT 왜 열광하는가? (0) | 2023.02.25 |
| 내 직업에 chatGPT 활용하는 꿀팁 (0) | 2023.01.25 |
- Total
- Today
- Yesterday
- 엑셀입력보호
- json파일편하게보는법
- 엑셀셀보호
- #웹개발
- #tuigrid #자바스크립트그리드 #행삽입 #행삭제 #웹개발팁 #프론트엔드개발 #javascriptgrid #데이터테이블 #ui개선 #그리드커스터마이징
- 자바스크립트 코드 기본지식
- 도면자동생성
- Bootstrap 5
- 구글드라이브API
- 1. #웹개발 2. #로트번호 3. #성적서보기 4. #ajax 5. #jquery 6. #php 7. #프론트엔드 8. #백엔드 9. #부트스트랩 10. #웹기능구현
- json파일형태보기
- #카테고리트리
- 오토핫키가이드
- 캐드자동작도
- 웹제작강의안2주차
- 효율적코딩방법
- #데이터무결성
- isset을 적용해야 하는 이유
- #textarea #자동높이조절 #ux개선 #웹개발 #프론트엔드 #자바스크립트 #html팁 #웹디자인 #uiux #코딩팁
- 엑셀보호
- ajax오류메시지
- coalesce는 한국어로 "코얼레스크" 또는 "코얼리스"
- #데이터베이스설계
- 티스토리챌린지
- 오블완
- #동적ui
- #계층형데이터
- #php에러해결 #php경고메시지 #nonwellformednumeric #php초보자팁 #웹개발에러 #프로그래밍디버깅 #php정규식 #코드디버깅팁 #웹개발문제해결 #php숫자형변환
- General error: 2031
- #트리구조
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |